 patch on Windows and Linux systems")
The impact of the Meltdown patch depends on the system workload. To understand when there is likely to be an impact, it’s important to understand basically what the patch actually does and how it affects some key entities associated with the CPU.
Tasks and task states
Executing tasks on a device will be in one of three states.
- Running user-mode code (this is the actual application logic itself)
- Running kernel-level code (this is, simplifying a bit, basically the operating system code)
- Waiting for some event (e.g, an I/O operation to complete, etc)
The Meltdown patch has an impact on the transition from user-mode code to kernel-mode code and back again.
I’ve simplified things a bit so if you’re a CPU geek, don’t take this as an absolute technical description of how things work. (in particular, I’ve referred to user page tables and kernel page tables as if these were separate things in the hardware, which is not really true – but it keeps the explanation simpler to imagine them as separate entities).
The key entities
The user page tables map so-called ‘virtual addresses’ through which the user code accesses memory to ‘physical addresses’ which are where that actual memory is inside the memory chips that are installed on the device.
The idea is that virtual addresses can remain unchanged while we move physical memory anywhere we like, without the code being aware of it. In fact, the physical memory might not even exist (because we are using all of it for other processes). When the code attempts to access memory that isn’t physically present, the operating system ‘page faults’ to bring that memory into physical memory. All this magic happens without the code being aware of it, because the CPU has special hardware to make it all happen.
Similarly, the kernel page tables map the kernel code virtual addresses to physical addresses.
The Translation Look aside Buffer, or TLB, is a special cache inside the processor which stores the most recently used mappings. It makes it much quicker to look up a virtual to physical translation so if code is repeatedly accessing the same part of memory (which is often the case), the TLB makes the translation process much faster.
The meltdown bug
The meltdown bug means that user-mode code can potentially access memory which only the kernel is allowed to see. In the diagram below, the green kernel page table entries (or more accurately the memory locations they point to) are not supposed to be accessible by the user-mode code because it lacks the privilege to do so. Unfortunately, the designers of the Intel CPU range made a design decision that means that under some circumstances, user-mode code can circumvent this hardware-level security and access kernel-mode memory.
To understand how Meltdown is possible, I recommend reading this page, because it explains the concepts clearly.
Because the meltdown flaw exploits a defect in the actual CPU hardware, the patch to mitigate it has to take fairly extreme measures. To understand how the patch works, see below.
How the patch mitigates against the Meltdown attack
Before the patch is applied, the system looks like this. Nothing changes when user-mode code calls into kernel code.
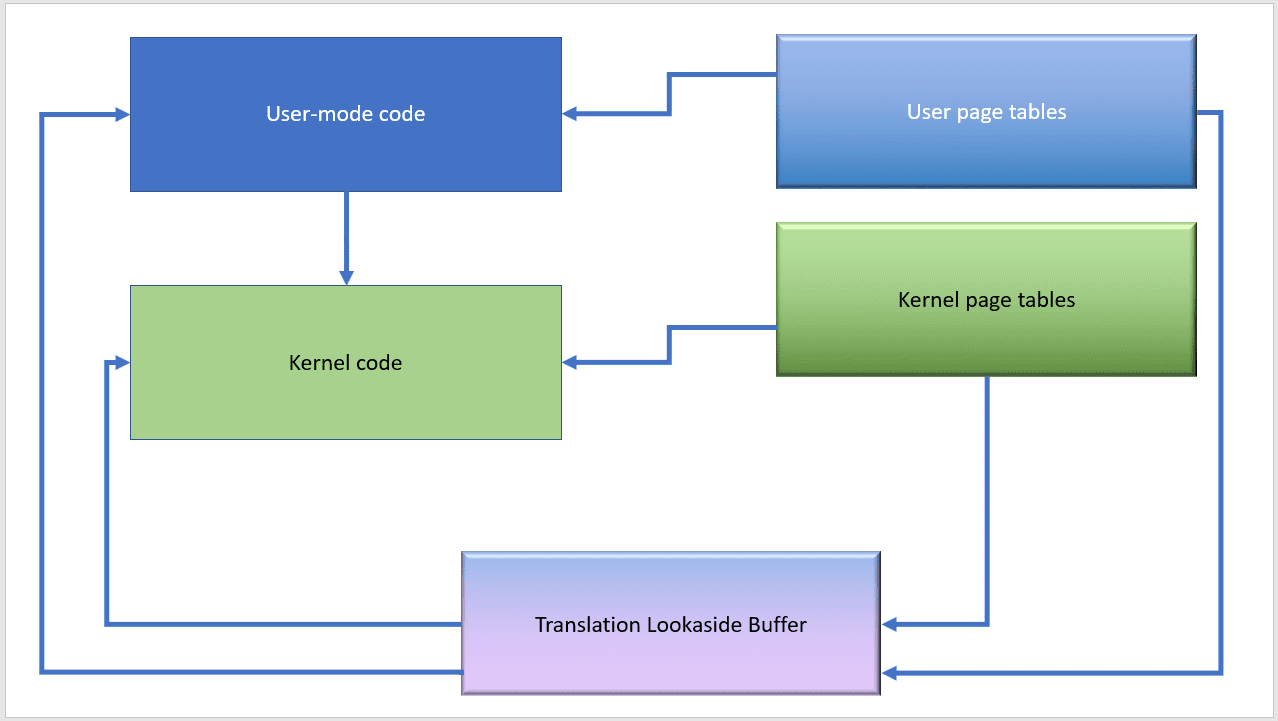
For any running process, the user and kernel page tables are present at all times and the TLB is used to cache recently-used mappings. Code transitions efficiently from user to kernel mode and back again because these entities don’t need to be touched.
After the meltdown patch is applied, things are more complex. When user-mode code is running, only a small piece of the kernel’s page tables are available. (the stub entries).
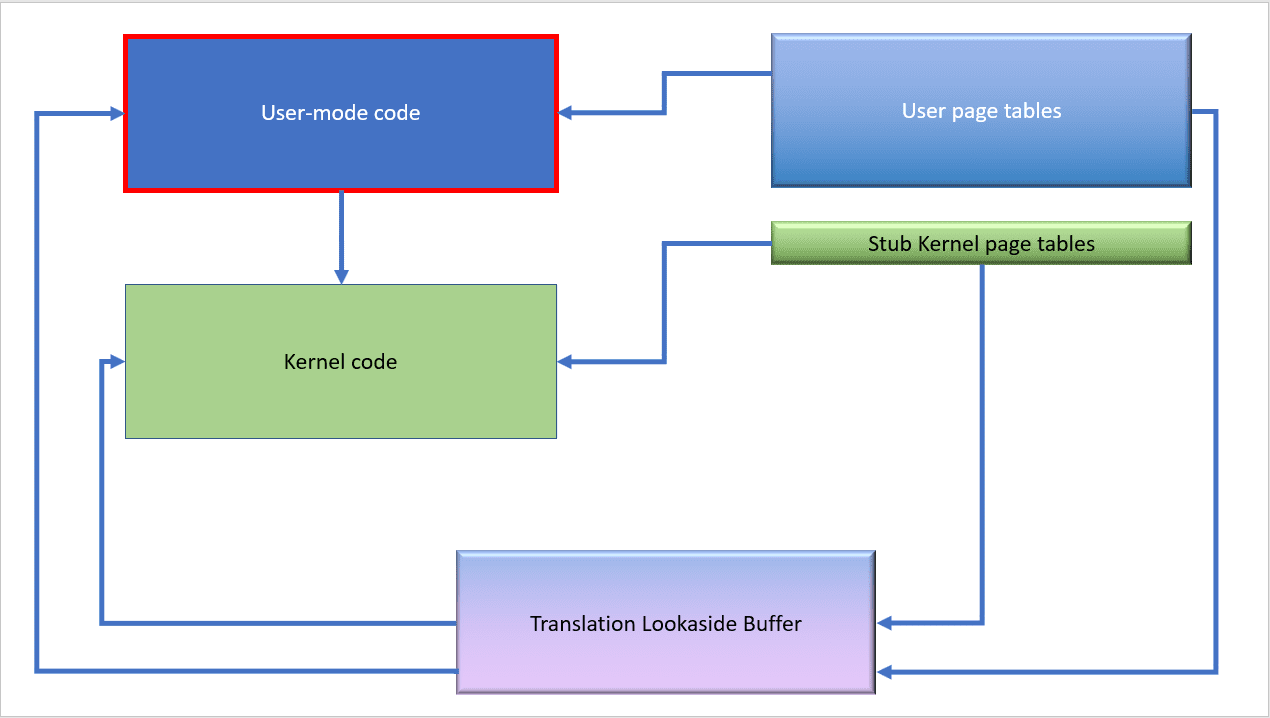
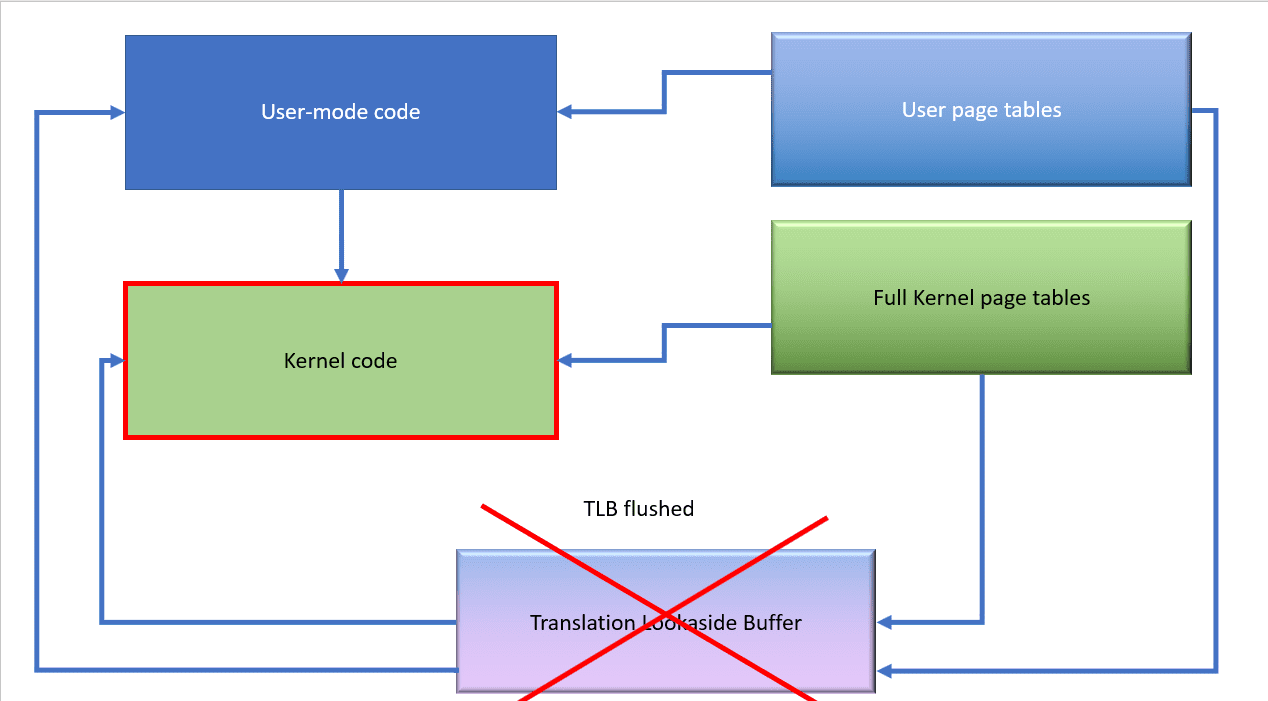
When the code transitions to kernel mode, the full kernel page tables are then made available.
We have to flush the TLB because this change may invalidate some entries inside it and any code that tried to use them would crash or misbehave.
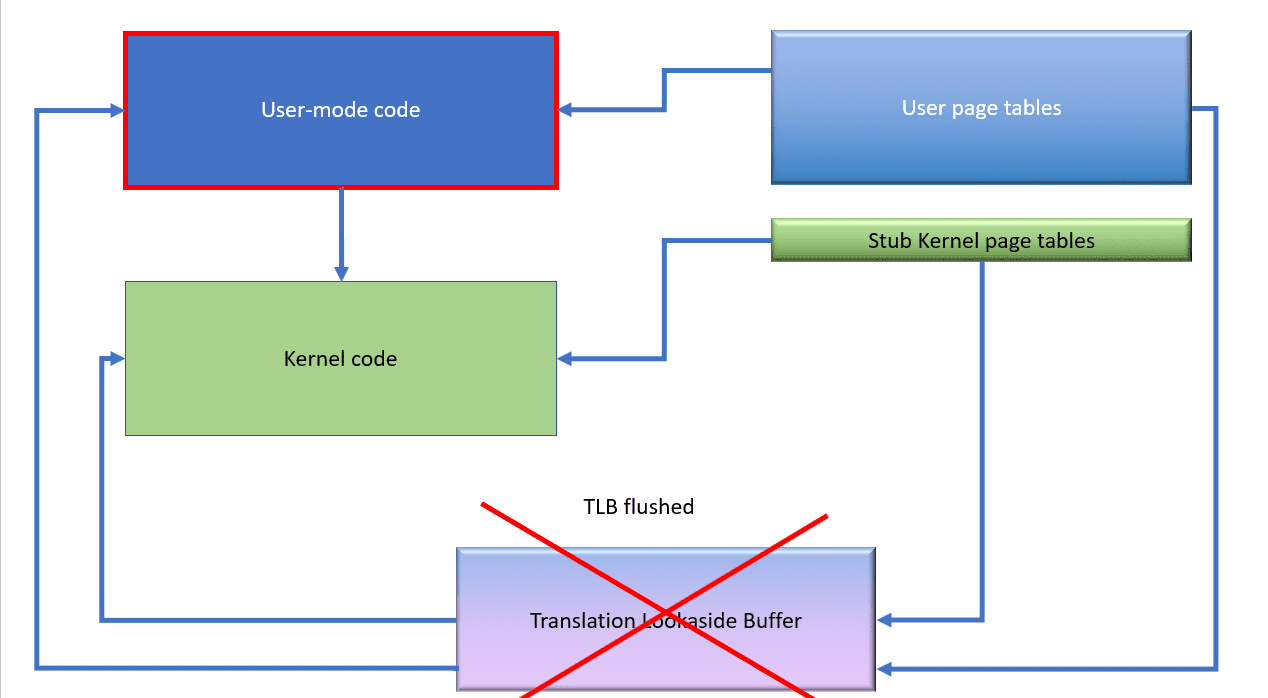
However, when the code transitions back to user mode, the kernel page tables are replaced with the stub tables again. Additionally, because the TLB might contain mappings that are no longer valid, we must flush entries out of it.
What is the impact of the patch?
Clearly, all this extra work makes the transition to and from kernel code slower. Therefore, code which makes a lot of kernel calls will be slowed down.
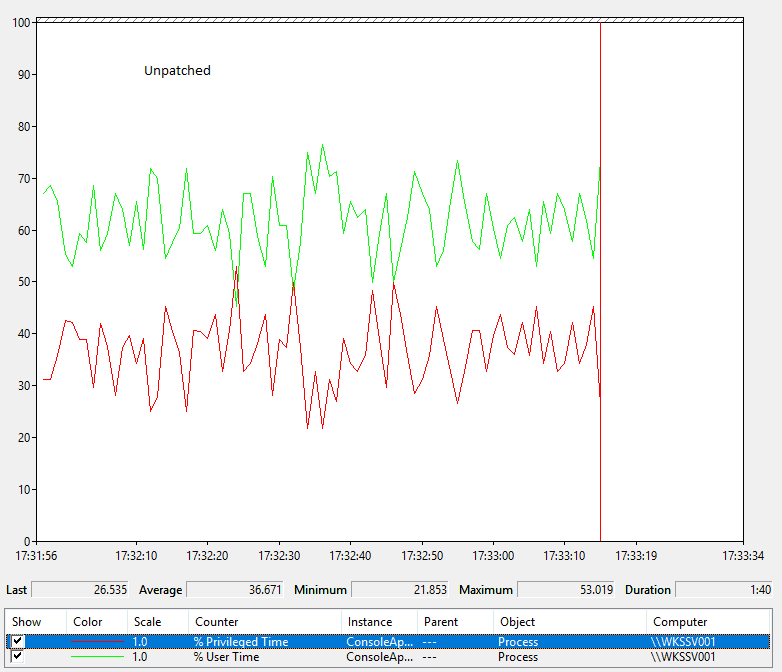
To have a closer look at this we wrote a very simple test program which makes a simple kernel call in a loop. We found that, after the patch, performance was about 10% slower. You can see how this looks before and after applying the patch by examining the graphs from the performance monitor application.
We are capturing two performance counters for the test process
- % User time is the percentage of time the code spends in user mode
- % Privileged time is the percentage of time the code spends in kernel mode
The two values should add up to 100% because the code is never waiting for anything (like I/O etc)
Before applying the patch
After applying the patch
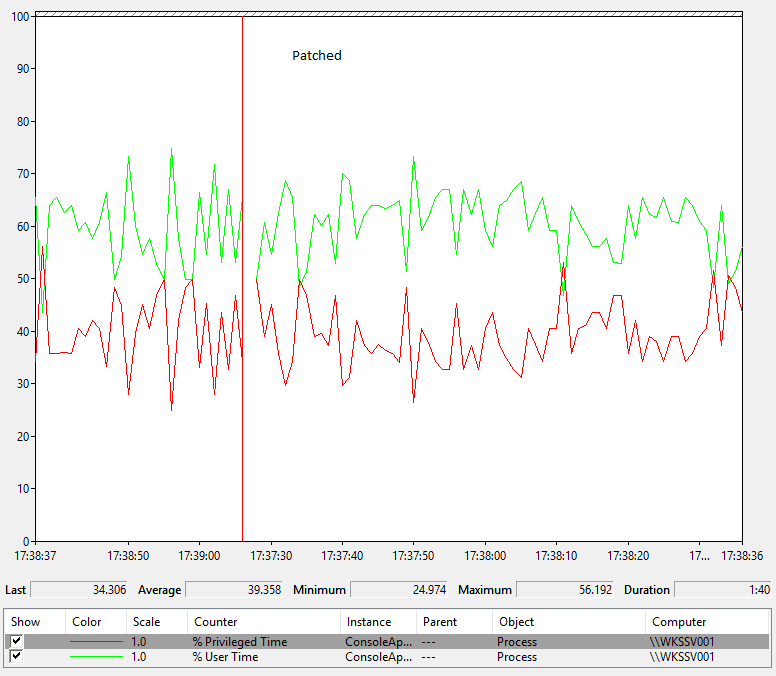
You can see that the average time the code spends in the kernel is now about 10% higher. Because of this, overall runtimes are about 10% longer or, looking at it another way, the server has 10% less capacity to run this code.
There is an additional potential performance hit that we don’t see in this simple test. This is to do with the TLB flushes. If user-mode code was accessing memory in a loop, it’s possible that the TLB flush will compromise performance slightly here, because now the page table mappings have to be fetched directly again, rather than from the TLB. This will incur a slight additional cost. The worst-case scenario would then be user-level code that accesses a lot of memory in a loop and makes a lot of kernel-mode calls from within that same loop. In this scenario, the TLB entries will have to be repeatedly rebuilt.
Also of course, one process that makes a lot of kernel-mode calls could adversely affect other processes, because the TLB is a shared resource.
(it’s also possible of course for the TLB flush to adversely affect kernel memory structure access, but this is much less likely because few kernel level calls have significant state between user-level calls.)
Modern CPUs that have the so-called ‘PCID’ feature can mitigate this issue to some extent because they can use this feature – which tags page table entries so the process associated with them can be retrieved efficiently – to avoid flushing the entire TLB on each mode transition.
What is the practical effect of this patch on I/O performance?
We used several disk benchmarking tools to examine the effect of the patch on disk I/O. (Crystal, Atto, and IOMeter). We used a very fast disk subsystem (SSD) to potentially maximize the effect, since slower disks will effectively limit the number of kernel calls that will be made to perform I/O because of the disk speed.
We found that, after the patch, disk I/O performance for sequential reads was largely unaffected but disk I/O performance for random reads (typically, multi threaded 4K block reads) was affected by between 10 and 15%.
We conclude that I/O intensive tasks (which may include network intensive as well as disk intensive tasks) may degrade by 10-15% because of applying the patch.
When does user-mode code make a kernel-mode call?
You might think that any time code called one of the so-called ‘Win32’ APIs that effectively make up the operating system, that this would result in a kernel-mode call. In fact, this is not the case. A lot of API calls are serviced entirely in user mode. For example, requesting the current tick count with the GetTickCount () API is entirely serviced in user mode. Conversely, closing a file handle requires a kernel-mode call.
If you profile a process with performance monitor and the % privileged time for that process is a significant amount, that process is potentially vulnerable to performance issues after applying the meltdown patch. If, on the other hand, the process makes few kernel calls (i.e % privileged time is consistently very low) then that process is unlikely to experience a performance slowdown because of applying the patch.
What about dedicated servers? Should I apply the patch?
Microsoft has suggested that a database server not running in a multi-tenanted environment, (e.g on bare metal or as a guest where the other guests are also trusted) may not need patching. This is a decision you would have to take on a per-case basis.
Web servers are more problematic. You cannot be sure who is accessing the server in most cases, so you will probably have no option but to patch it. However, web servers can make significant I/O and network demands and may experience performance slowdowns as a result.
We will keep you posted as any other updates become available.



